In our last post, we laid out the challenges facing organizations in keeping their microservices environment running smoothly after making the move to Kubernetes.
In this post, we provide a framework for the way forward.
Establishing a New Set of Best Practices and Tools for the Microservices Reality
Despite microservices being in use for a couple of years now, which in tech years can feel even longer, there is yet to be a real update to the standard list of best practices and tools in this space.
There are now some new best practices for addressing health checks, CI/CD issues, and how to best utilize monitoring tools that are out there, but they are not yet widely known or used.
We need to think about widening the circle of people that are able to make fixes when necessary. In the legacy systems with their complexity, this knowledge was mostly held by those few who were intimately familiar with the structure of the core application, and that was sufficient.
But now we have the opportunity, and frankly, the necessity, to think about how we can take the initiative to set the markers for how a microservices environment should be maintained.
Among our new best practices and tools that are accessible to everyone should include:
Best practices:
- Health checks
- Tests that look at the base level, scale, and resilience of the apps
Tools:
- Distributed tracing – Track requests throughout your microservices environment
- Log aggregation – Make logs from all systems visible in one place
- APM – Metrics on infrastructure and application levels
These technologies and practices are already in use by some, but they only provide us a part of the picture of where we should be heading. They have proven themselves out in the monolith model, but still need some significant tweaking before they are ready for the distributed reality of microservices.
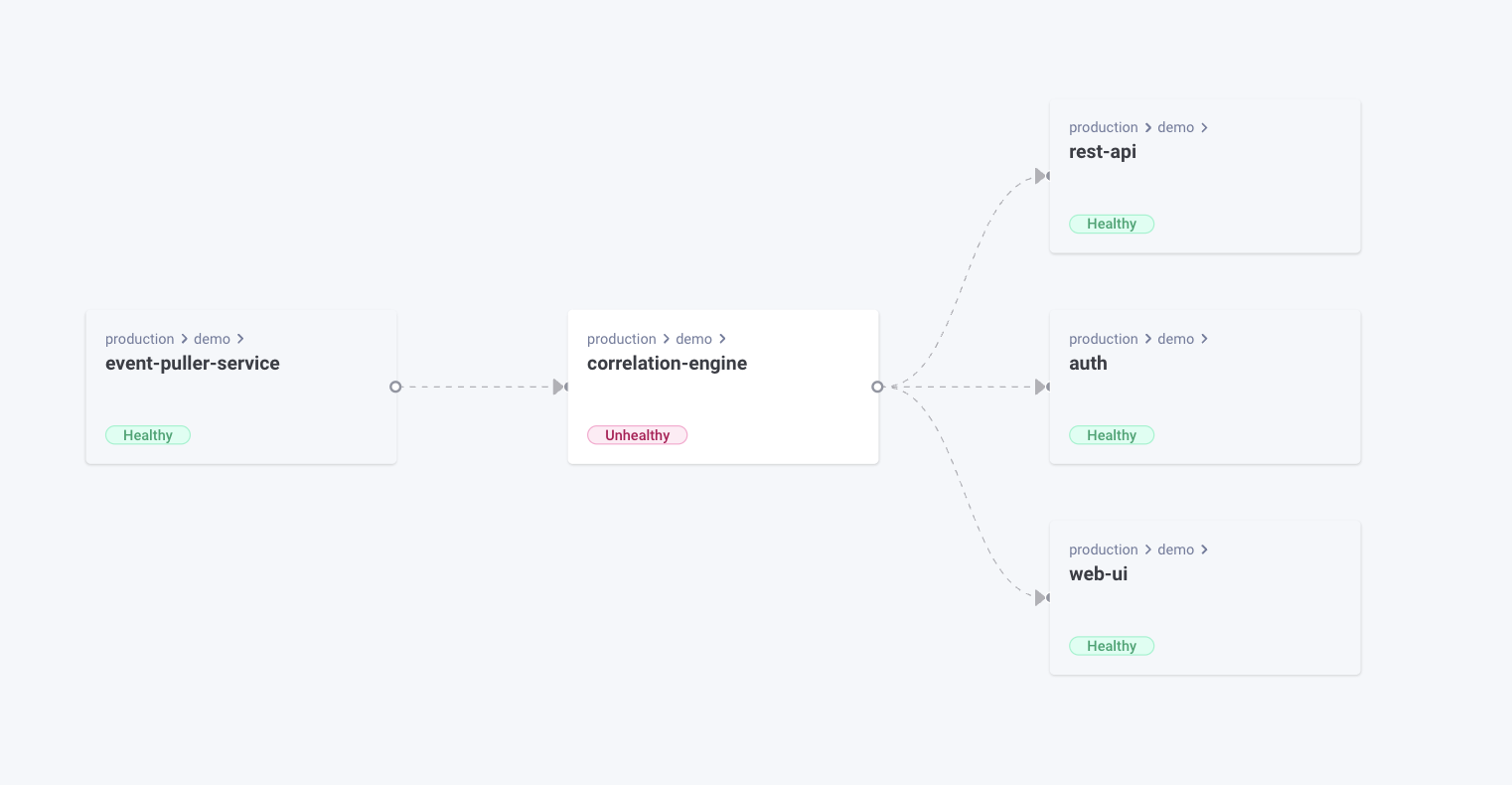
The primary issue here is that the scale of relevant information pertaining to the applications spread out across the organization is simply too wide for everyone who needs to keep them in good working order to keep track of reliably.
Where Do We Need to Go Next?
When issues arise, we are rarely so lucky as to have the person who knows the product inside and out be the one to actually pick up the call. What follows in both crisis mode and even day-to-day troubleshooting is that IT professionals end up needing to quickly get caught up to speed before they can start diagnosing the problem.
If we want to avoid unnecessary additional downtime, then we need to find ways to get everyone on the same page faster. And we mean everyone. From Dev to DevOps to
In order to do this, we need to provide them with the necessary tools that offer them the context to those changes in their applications and environments — and they have to be better than just throwing all of the info into Slack.
These tools should allow our teams to:
- Provide a single-pane-of-glass that has visibility over all the applications, no matter how dispersed they may be.
- Track changes in our environment so that we can identify the likely causes of the issue. Even if we weren’t the ones that made said change.
- Make it easy enough for someone who is not the primary maintainer of an application to step in and familiarize themself with where the various bits and pieces are located.
Our end goal should be to simply speed up remediations for all members of our wider team. Just as it was before making the move to Kubernetes.
Getting your organization over to Kubernetes and the microservices environment is the first step. But it is the first of many. Now the real challenge of keeping apps up and running over the long haul begins.