What Is Kubernetes?
Kubernetes is an open source platform for managing Linux containers at large scale, commonly used to manage workloads in cloud environments. Containers are lightweight units that run on the host’s common shared operating system but are isolated from each other. Kubernetes helps manage containers as a cluster, providing powerful, customizable automation capabilities.
Application developers, IT system administrators, and DevOps engineers use Kubernetes to automatically deploy, scale, maintain, schedule, and operate multiple containers. Kubernetes can be used to manage any type of workload. Today it is the most common method for managing microservices applications with a large number of service instances, each deployed as a container.
Kubernetes can be deployed in all public clouds and also in a local data center, creating a private cloud. This makes Kubernetes an ideal platform for hosting cloud-native applications that can scale quickly and be easily ported between environments.
Kubernetes Architecture and Components
When you deploy Kubernetes, it creates a cluster consisting of one or more worker machines, called nodes, that run containerized applications.
Worker nodes host pods, which are the main component used to manage application workloads. A pod runs one or more containers. The Kubernetes control plane manages the worker nodes and pods in the cluster.
In a production environment, the control plane typically runs on multiple machines, and clusters run on multiple nodes (up to thousands of nodes), to provide fault tolerance and high availability.
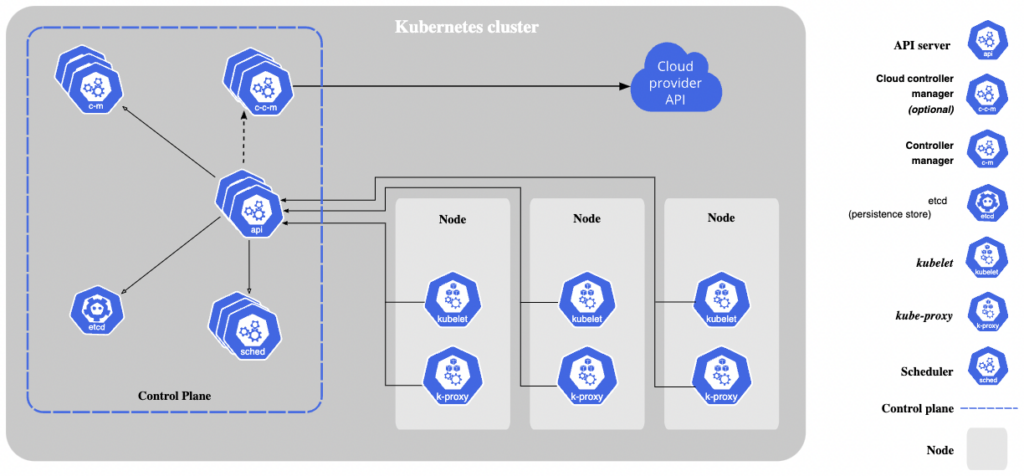
Image Source: Kubernetes
Kubernetes Control Plane
The control plane is responsible for managing cluster processes. The primary processes are kube-apiserver, etcd, kube-scheduler, kube-controller-manager, and cloud-controller-manager. In some cases, third-party solutions are used to add features like cluster-level logging, cluster DNS management, and resource monitoring.
kube-apiserver
kube-apiserver is a core component of a Kubernetes cluster, responsible for handling internal and external traffic.
kube-apiserver is the only component connected to the etcd database. It serves as the primary front-end to the shared state of the cluster. It is primarily responsible for handling API calls concerned with authentication, authorization, and admission control.
etcd Database
etcd is a database system for storing cluster state, network information, and other persistent information. It stores information in the form of key-value pairs. These key-value pairs are not overwritten when updates are required—instead, etcd creates a new key-value pair one and appends it to the end, marking the older pair for later deletion.
etcd supports most HTTP libraries and curl. When you make updates to the etcd database, they are immediately reflected in the kube-api server.
kube-scheduler
kube-scheduler uses several scheduling algorithms to determine which pods should be deployed to which worker nodes. In most scheduling patterns, it checks the node’s resource availability and allocates available resources based on the request type.
Any node that meets certain requirements is called an “eligible node”. If a node is not currently eligible for a pod, the pod will not be scheduled until an eligible node becomes available.
kube-controller-manager
This is the control plane component that runs controller processes, which are responsible for adjusting cluster state to match a desired configuration. Logically, each controller is a separate process, but to reduce complexity, they are all compiled into one binary and run in one process known as kube-controller-manager.
Here are common types of Kubernetes controllers:
- Node controller—responsible for notification and response when a node is down.
- Job controller—creates a pod that runs a job, which is a one-time task, and shuts it down when the job is complete.
- Endpoint controller—configures endpoint objects which enable pods to connect to services. A service is an abstraction that allows entities, both inside and outside the Kubernetes cluster, to connect to pods without knowing their specific IP.
- Service account and token controllers—create a default account and API access token for a new namespace.
cloud-controller-manager
cloud-controller-manager is similar to kube-controller-manager except that it interacts with cloud-specific APIs. The main difference is that kube-controller-manager handles components that only interact with the cluster, while cloud-controller manager handles those that interact with a public cloud platform.
In later versions of Kubernetes, it handles some controller actions that were previously handled by kube-controller-manager.
Node Components
Node components run on each Kubernetes node, maintain running pods, and provide the Kubernetes runtime environment.
kubelet
Each compute node contains a kubelet, an agent that communicates with the control plane to determine if the pod’s containers are running. When the control plane needs to perform a specific operation on a node, the kubelet receives the pod specification through the API server and executes the operation. It then checks that the relevant containers are healthy and running.
kube-proxy
Each compute node includes a network proxy that facilitates Kubernetes network services. This is kube-proxy, which either forwards traffic itself or relies on the operating system’s packet filtering layer to handle network traffic inside and outside the cluster.kube-proxy runs on each node to serve traffic from external entities and manage subnets for individual hosts. It it not only a network proxy, but can also act as a service load balancer on the node, managing network routing of UDP and TCP packets, and routing traffic to all service endpoints.
Add-on Components
Kubernetes has add-ons that use Kubernetes resources (such as DaemonSets, StatefulSets, or deployments) to implement cluster functionality. Add-on resources typically reside in the kube-system namespace (a namespace reserved for control plane components), because they provide cluster-level functionality.
Cluster DNS
Cluster DNS is a DNS server that provides DNS records to Kubernetes. This is an add-on but is very commonly used, as it provides a lightweight service discovery mechanism.
Containers launched on Kubernetes already have a DNS server for DNS lookups.
Kubernetes Dashboard (Web UI)
The Kubernetes Dashboard is a generic web-based UI for a Kubernetes cluster. Users can manage and troubleshoot the cluster itself as well as the applications running within it.
Cluster-level Logging
Application logs help you understand what is going on in your application. Logs are especially useful for debugging problems and monitoring cluster activity.
In a Kubernetes cluster, logs require separate storage and an independent lifecycle that is not dependent on nodes, pods, or containers. The reason is that if a node, pod, or container terminates, the logs should still be available. This concept is called cluster-level logging.
A cluster-level logging architecture requires a separate backend to store, analyze, and query the logs. Kubernetes does not provide a native storage solution for log data. Instead, there are several logging solutions that integrate with Kubernetes.
The Kubernetes Storage Model
By default, Kubernetes storage is ephemeral, meaning that when a resource shuts down, its storage also terminates and the data is lost.
However, Kubernetes supports many forms of persistent storage, both on-premises and in the cloud. This includes on-premise persistent storage, and files, block, or object storage from public cloud providers.
Storage can be referenced directly from pods, but this is not recommended as it violates the container/pod portability principle. Kubernetes provides the concept of PersistentVolumes (PVs) and PersistentVolumeClaim (PVCs), which separate the storage implementation from functionality, allowing Pods to access storage in a portable way.
PVs are where administrators define storage volumes and their performance and capacity parameters. A DevOps engineer uses PVCs to describe the storage required by an application. Kubernetes then retrieves available storage from the defined PV and binds a PVC to it.
Since the PVC is defined in the Pod’s YAML, the declaration is propagated along with the pod. Requesting storage can be as simple as specifying just the storage capacity and tier.
PVs can be grouped into storage classes, which are Kubernetes application programming interfaces for setting storage parameters. A storage class specifies the name of the volume plug-in, the storage provider (for example, a cloud service), and the CSI driver used.
Container Storage Interface (CSI) is a driver specification that allows containers running within Kubernetes to interact with cloud storage services and standard equipment from storage vendors.
Learn more in the detailed guide to Kubernetes storage
The Kubernetes Network Model
Each Pod in a cluster has a unique cluster-wide IP address. This means that you don’t need to explicitly create links between pods, and you rarely need to map container ports to host ports.
This creates a clean, backwards-compatible model that lets you treat pods as if they were physical hosts or virtual machines (VMs) in terms of port assignment, naming, service discovery, load balancing, application configuration, and migration.
Kubernetes imposes the following two requirements on network implementations (unless you define an explicit network segmentation policy):
- Pods can communicate with any other pod on any other node without network address translation (NAT).
- Agents on a node (system daemons, kubelets, etc.) can communicate with all pods on the same node.
Kubernetes IP addresses exist within a pod scope. Containers in a pod share a network namespace that contains IP and MAC addresses. This means that all containers in a pod can access each other’s ports using the localhost. This also means that a pod’s containers must coordinate port usage, just like a VM’s processes. This is called the “IP per pod” model. The specific implementation will depend on the container runtime you are using.
Benefits of the Kubernetes networking model
A primary benefit, and a key motivation for this model, was to make it easy to port applications from VMs to containers. If a workload previously ran on a VM, the VM had an IP and could communicate with other VMs on the local network. Kubernetes provides similar functionality.
In addition, the Kubernetes networking model enables containers in pods to communicate via loopback; enables pods to communicate with each other; and enables service resources to expose applications running in a pod for access outside the cluster. In the same way, services can expose services for use within the cluster.
Learn more in the detailed guide to:
Deploying Workloads in Kubernetes
What Is a Kubernetes Deployment?
The process of manually updating containerized applications is time consuming and tedious. To upgrade a service to the next version, you would need to start the new version of the pod, stop the old version of the pod, check if the new version starts successfully, and if not, roll back manually to the old version.
Performing these steps manually can involve human error, and even if you script them, the scripting could fail to work correctly, all of which creates bottlenecks in the release process.
With the Kubernetes deployment object, this process becomes automated and repeatable. A deployment enables updating workloads in a fully automated way, managed by the Kubernetes control panel, and the entire update process is done server-side with no client interaction.
A Kubernetes deployment is a resource object that provides declarative updates to applications. Deployments allow you to describe the lifecycle of your application, including the container images it uses, how many pods it requires, and how to update it.
Like any Kubernetes object, a deployment is a way to tell the Kubernetes system what your cluster’s workload should look like. When an object is created, the cluster checks if the object exists, creates it if not, and maintains the desired state described in the object’s configuration. A deployment runs any number of pods and is always available.
You can use Kubernetes deployment objects to deploy or update ReplicaSets or pods, rollback to a previous deployment version, scale deployments up or down, and pause or resume a deployment.
Learn more in the detailed guide to Kubernetes Deployment
Kubernetes Deployment vs. StatefulSets
A StatefulSet is a workload API object for managing stateful applications. Kubernetes users don’t need to worry about how pods are scheduled—they can deploy pods sequentially, attach them to persistent storage volumes, and each pod maintains its own persistent network ID.
Like deployments, StatefulSets manage pods based on a container specification. However, they differ from deployments in that they maintain a static ID for each pod. Pods can be created according to the same specification, but are not interchangeable, and are assigned a unique identifier that persists even as they are scheduled to other nodes.
The main differences between Deployment and StatefulSet are:
| Deployments are used for stateless applications | StatefulSets are used for stateful applications |
| Pods in a deployment are interchangeable | Pods in a StatefulSet have a unique identifier |
| Deployments require a service to facilitate interaction with pods | in StatefulSets a headless service manages the pod’s network IDs |
| In a deployment, all replicas share volumes and PVCs | in a StatefulSet, each pod has its own volume and PVC |
Learn more in the detailed guide to Kubernetes Statefulset
Kubernetes Deployment vs. Kubernetes Helm
Kubernetes Deployment and Helm are both tools used to manage applications in a Kubernetes environment. But they serve different purposes and have different strengths and weaknesses.
Kubernetes Deployment is a core feature of Kubernetes. It’s used to manage stateless applications and services. With a Deployment, you can describe the desired state of your application, and Kubernetes will automatically manage the underlying Pods to ensure that the state of your application matches your specifications.
On the other hand, Helm is a package manager for Kubernetes. With Helm, you can package your Kubernetes applications into charts, which are collections of files that describe a related set of Kubernetes resources. Helm charts make it easy to deploy and manage complex applications, and they also support versioning so you can roll back to a previous version of your application if necessary.
While Kubernetes Deployment is a powerful tool for managing stateless applications, it lacks some of the features that Helm offers. For example, Helm supports dependencies between different components of your application, and it provides a way to manage configuration information that can be shared across multiple environments.
Learn more in the detailed guide to Kubernetes Helm
Kubernetes Autoscaling
When deploying a specific workload or an entire Kubernetes cluster, you plan capacity based on known application loads. However, these loads can change over time, or might spike unexpectedly. When this happens, you could run out of computing resources, slowing down services and frustrating users.
Manually allocating resources is inefficient and does not allow rapid response to changes in demand. Kubernetes autoscaling can help. Kubernetes provides several autoscaling tools that can help you automatically provision more or less resources for workloads, or for your entire cluster
The primary autoscaling mechanisms in Kubernetes are:
- Horizontal pod autoscaling (HPA)—scales pods across multiple nodes if they need more capacity, or terminates pods on some nodes if they need less capacity.
- Vertical pod autoscaling (VPA)—increases the resource requirements of a pod, ensuring it is scheduled to a node with more resources available or more powerful hardware capabilities (or conversely, reduces resource requirements if the pod is overprovisioned).
- Cluster Autoscaler—automatically scales up the cluster by adding nodes, and terminates nodes when they are not running any pods (this works by interfacing with cloud services like Amazon EC2). This ensures that the cluster has enough capacity to meet the requirements of all current workloads.
Learn more in the detailed guide to Kubernetes autoscaling
Kubernetes Dashboards
When it comes to managing your Kubernetes clusters, there are several graphical user interfaces (GUIs) available. The Kubernetes Dashboard is a web-based UI for Kubernetes clusters, built into the Kubernetes distribution. It allows users to manage and troubleshoot applications running in the cluster, as well as the cluster itself. While the Kubernetes Dashboard offers a lot of functionality, it can be a bit overwhelming for beginners.
Komodor offers a free-forever, next-generation Kubernetes dashboard that helps you manage and troubleshoot Kubernetes workloads across multiple clusters.
Komodor provides automated playbooks for every K8s resource, and static-prevention monitors that enrich live & historical data with contextual insights to help enforce best practices and stop incidents in their tracks. By baking K8s expertise directly into the product, Komodor is accelerating response times, reducing MTTR and empowering dev teams to resolve issues efficiently and independently.
Learn more about Komodor or get started now!
Another popular dashboard solution is Kubernetes Lens.
Managing Kubernetes Costs and Performance
Managing costs and performance in a Kubernetes environment can be challenging, but it is vital for maintaining the health and efficiency of your applications. Kubernetes provides several tools to help you monitor and control your resources.
Resource requests and limits are one of the primary means of managing costs and performance in Kubernetes. By setting resource requests, you tell Kubernetes the minimum amount of resources that a container needs. On the other hand, by setting limits, you specify the maximum amount of resources a container can use.
Another way to manage costs is by using Kubernetes namespaces to group and isolate resources. This allows you to allocate resources to different teams or projects and track their usage.
Performance in Kubernetes can be managed by using effective logging and monitoring. Kubernetes provides built-in tools for logging and monitoring, like the Kubernetes Dashboard, and supports integration with external monitoring tools like Komdor.
Learn more in the detailed guides to:
Kubernetes in the Cloud
It is common to deploy Kubernetes clusters on public cloud resources. Let’s see how this works with the leading cloud providers—Amazon, Microsoft Azure, and Google Cloud.
Kubernetes on AWS
When running Kubernetes on Amazon Web Services (AWS), you can choose to self-manage your Kubernetes infrastructure on Amazon EC2 in an infrastructure as a service (IaaS) model, or use Amazon Elastic Kubernetes Service (EKS) to get an automatically provisioned and managed Kubernetes control plane.
Either way, Amazon provides security, elastic scalability, and high availability for your Kubernetes cluster, and the open source community has integrated Kubernetes with AWS services like Virtual Private Cloud (VPC), Identity and Access Management (IAM), and Amazon’s native service discovery.
Here the primary options for deploying Kubernetes on AWS:
- Amazon EC2 —comprehensive management of Kubernetes deployments. Configure and run Kubernetes nodes on compute instance type of your choice.
- Amazon EKS —a cloud-based container management service that natively integrates with Kubernetes to deploy applications. The EKS service uses Kubernetes to automatically manage and scale clusters of infrastructure resources on AWS. Amazon EKS lets you use Kubernetes without installing, operating, or managing container orchestration software.
- Amazon elastic container registry (ECR) —a fully managed Docker container registry that lets you store, share, and retrieve container images for use in Kubernetes clusters.
Learn more in the detailed guide to Kubernetes on AWS
Kubernetes on Azure
Microsoft Azure is Microsoft’s public cloud computing platform. It provides various cloud services such as computing, analytics, storage, and networking. In the context of Kubernetes, Azure offers the following service options:
- Azure Virtual Machines (VMs)—like in AWS, you can run Azure VMs and use them to install and manage components of a Kubernetes cluster, as a self managed option.
- Azure Kubernetes Service (AKS)—lets you deploy managed Kubernetes clusters on Azure. AKS reduces the complexity and operational overhead of managing Kubernetes by shifting most responsibilities to Azure. Azure handles critical tasks such as health monitoring and maintenance, managing the Kubernetes control plane, leaving you to maintain Kubernetes worker nodes.
- Azure container instances (ACI)—provides the fastest and easiest way to run containers on Azure without having to manage virtual machines or use advanced services. ACI supports Kubernetes, and is a lightweight option for running smaller Kubernetes clusters.
- Azure container registry (ACR)—a managed private Docker registry service based on the open source Docker Registry 2.0. Lets you create and maintain your own, private container registry to store and manage Docker container images and related artifacts.
Learn more in the detailed guide to Kubernetes in Azure
Kubernetes on Google Cloud
Google Cloud is a set of public cloud computing services provided by Google. The platform includes a variety of managed services for developing compute, storage, and software services running on Google hardware.
Google Cloud provides two main options for running Kubernetes:
- Google Kubernetes Engine (GKE)—GKE provides a hosting environment for deploying, managing, and scaling containerized applications. A GKE environment consists of multiple Google Compute Engine (GCE) instances that are grouped together to form a cluster. Like EKS and AKS, GKE fully manages the Kubernetes control plane and handles critical operational tasks for a Kubernetes cluster.
- Google Anthos—a cloud-agnostic hybrid container environment that lets you run managed Kubernetes clusters in any environment. Anthos is a software product that lets you bridge the gap between on-premise data centers and cloud environments, using container clusters instead of cloud virtual machines (VMs).
Kubernetes and CI/CD
CI/CD is a software development practice that enables developers to continuously integrate and deploy code changes. In continuous integration (CI), developers integrate their code changes into a shared repository frequently, usually several times a day. Each integration is verified by an automated build, which can include tests to ensure that the new code does not break the build or introduce new bugs.
In continuous deployment (CD), code changes are automatically built, tested, and deployed to production. This allows developers to continuously deliver new features and updates to users, without the need for manual intervention.
When used together, Kubernetes and CI/CD can help developers build and deploy applications more quickly and reliably. For example, a developer might use a CI/CD pipeline to build and test their code, and then use Kubernetes to deploy the application to production. Kubernetes can then manage the running application, scaling it up or down as needed and automatically restarting or rescheduling failed containers.
Kubernetes and CI/CD are often used together in cloud-native architectures, where applications are built as microservices and deployed in containers. In these architectures, CI/CD pipelines are used to build and deploy individual microservices, while Kubernetes is used to manage the overall application. This allows developers to build and deploy applications more quickly and easily, while still being able to manage and scale them in production.
Learn more in the detailed guide to CI/CD
GitOps and Kubernetes
GitOps is a new way to manage Kubernetes clusters and deploy applications to production. It is a development method that uses Git as a single source of truth, using declarative configuration to represent both infrastructure and applications.
GitOps uses a software agent to identify differences between the configuration stored in Git and resources actually running in your cluster. If there is a discrepancy, this agent automatically updates or rolls back the cluster. Using Git at the heart of the delivery pipeline, developers can use familiar tools to make changes to applications and infrastructure, simply by creating a pull requests, accelerating and simplifying operational tasks.
GitOps and declarative configuration
Kubernetes with Gitops is just one example of many modern cloud-native tools that are “declarative”, treating configuration as code. Declarative means that resources are defined as a set of requirements, rather than a list of instructions that define how to create them (as in a traditional script).
When these declarative configurations are versioned in Git, you have a single source of truth, which lets you easily deploy applications to a Kubernetes cluster and roll them back if necessary. This makes rollback easier—you can use “Git revert” to revert to a previous application state. In the event of a disaster, the Git repository stores the state of the entire cluster, making it easy to restore workloads.
GitOps and security
When system declarations are stored in a version control system and serve as a trusted source of information, there is one place from which to drive the entire cluster. Git provides strong security guarantees, allowing you to sign commits with an SSH key, so you can be certain who is the author and what is the origin of your code.
Once you have declared a state in Git, the system automatically applies changes to that state. A primary benefit of this approach is that you don’t need cluster credentials to make changes to a Kubernetes cluster (i.e. no more “kubectl” commands). GitOps has an isolated environment with externally-defined state definitions. This creates a separation between the CI and CD environment, which is highly beneficial to security.
GitOps and reliability
When a cluster’s system state is declared and placed under version control, software agents can notify when reality does not match expectations.
GitOps agents allow the entire system, or any part of it, to self-heal. This is not “self healing” in the sense of routine errors in nodes or pods, which are anyway handled by Kubernetes. It is healing in a broader sense, such as recovering from human error or software bugs. In this case, the software agent acts as an operational feedback and control loop, which restores the cluster to the desired state.
Learn more in the detailed guide to Gitops
What Is Argo?
Argo is an open source project managed by the Cloud Native Computing Foundation (CNCF). It is used to build and manage applications on Kubernetes using a GitOps-style continuous delivery (CD) workflow. A unique feature of Argo is that it is Kubernetes-native, designed from the ground up for modern containerized environments.
Argo allows you to automate deployments and releases, and simplify rollbacks in case something goes wrong.
The Argo project consists of 4 different projects: Argo Workflows, Argo CD, Argo Rollouts, and Argo Events.
Argo CD
Argo CD is a Kubernetes native continuous deployment (CD) tool. Unlike external CD tools that only allow push-based deployment, Argo CD can pull updated code from a Git repository and deploy it directly to Kubernetes resources. This allows developers to manage infrastructure configuration and application updates from one system.
Argo CD offers the following key features:
- Deploy applications manually or automatically to a Kubernetes cluster.
- Automatically synchronize the application state to the current version of the declarative configuration.
- Web-based user interface and command line interface (CLI).
- Ability to visualize deployment issues and detect and correct configuration drifts.
- Role-Based Access Control (RBAC) to enable multi-cluster management.
- Single sign-on (SSO) with multiple providers and protocols.
- Triggering actions with webhooks via GitLab, GitHub, or BitBucket.
Learn more in the detailed guide to Argo CD
Argo Workflows
Argo Workflows is an open source container-native workflow engine for orchestrating parallel tasks on Kubernetes. Argo workflows are implemented as Kubernetes CRDs. With Argo Workflows, you can:
- Define a workflow where each step in the workflow is a container.
- Model multi-step workflows as a series of actions, or use graphs (DAGs) to capture dependencies between actions.
- Easily run compute-intensive jobs for machine learning and data processing on Kubernetes.
- Run CI/CD pipelines natively on Kubernetes without configuring complex tooling.
Learn more in the detailed guide to Argo Workflows
Argo Rollouts
Argo Rollouts is a set of Kubernetes controllers and CRDs that provide advanced deployment features for Kubernetes such as blue-green deployment, canary deployment, canary analytics, experiments, and incremental serving capabilities.
Argo Rollout can integrate with Kubernetes ingress controllers and service mesh platforms, leveraging traffic shaping to incrementally switch traffic to new versions during updates. It can also obtain metrics from other providers, validate KPIs that indicate success of a release, and drive automated promotions or rollbacks based on these metrics.
Learn more in the detailed guide to Argo Rollouts
Argo Events
Argo Events is a dependency manager for Kubernetes that lets you define dependencies from different event sources, such as webhooks, Amazon S3, time-based schedules, streaming events, and so on—and trigger Kubernetes objects after an event dependency is resolved.
Argo Events is not useful by itself—you need to integrate it with a system that can execute workflow steps. For example, you can set up Argo Events with Argo Workflows to orchestrate Kubernetes jobs in parallel.
Learn more in the detailed guide to Argo Events
Kubernetes and Hybrid Cloud
A hybrid cloud is a combination of a public cloud and a private cloud, allowing organizations to take advantage of the benefits of both environments.
Kubernetes can be used to manage containers in a hybrid cloud environment, allowing organizations to run their applications in both the public cloud and their own on-premises data center. This provides the benefits of the public cloud, such as scalability and access to a wide range of services, along with the control and security of a private cloud.
Kubernetes can help organizations manage their hybrid cloud infrastructure by providing a common platform for deploying, scaling, and managing applications in both environments. Kubernetes can also help organizations manage the movement of applications and data between public and private clouds, ensuring that applications run optimally in each environment.
Learn more in the detailed guide to Hybrid IT
Kubernetes Security
Kubernetes has some security benefits, like easy version control, but its complexity and popularity make it an attractive target for attackers. One way for developers to address Kubernetes security is to consider how to implement security during each stage of the DevOps pipeline.
Security in the Build Stage
Kubernetes security starts when you build the code for container images. A secure environment requires shifting security left, including testing and assessing code-related risks. During the build stage, you must ensure the container images are current and don’t have vulnerabilities.
You don’t always have a list of the open source components included in the container, so scanning for open source libraries and dependencies is important. Once you’ve identified all the components in play, it is possible to detect known vulnerabilities, identify the images at risk of new vulnerabilities, and track open source license compliance.
Regular base image scanning is an important first step to securing the Kubernetes environment.
Security in the Deployment Stage
When you deploy Kubernetes, you have powerful controls to secure applications and clusters, but configuring these controls can be challenging and requires Kubernetes expertise. Avoid using defaults to reduce exposure, restrict user permissions, limit access to nodes, and segment the network to control communication between containers.
Scanning during deployment is important to ensure base image security, including continuous vulnerability scans and environment updates. Ensure that all images used are from allow-listed registries.
Security in the Production Stage
Ensuring application security at runtime is more complex and requires implementing a networking layer with the CNI. In multi-tenant networks, every namespace in a Kubernetes cluster has private addressable subnets and can only access other pods exposed as services.
Most next-gen networking layers have policies deployable via Kubernetes—these policies let cluster admins determine network access control lists to control access to services and ports.
Learn more in the detailed guides to:
Kubernetes Troubleshooting
Kubernetes troubleshooting is the process of identifying, diagnosing, and resolving issues with a Kubernetes cluster, node, pod, or container. More broadly, Kubernetes troubleshooting includes effective error management and actions to proactively prevent problems with Kubernetes components.
Kubernetes is a complex system, and troubleshooting a problem in a Kubernetes cluster is equally complex. Diagnosing and resolving issues can be challenging even on small local Kubernetes clusters. The root cause of a problem could be a single container, one or more pods, a controller, a control plane component, one or more infrastructure components, or some combination.
This problem is exacerbated in large production environments with low visibility and many moving parts. Teams must use multiple tools to gather the data they need to troubleshoot, and in some cases, additional tools to diagnose and resolve issues they discover.
To make matters worse, Kubernetes is often used to build microservices applications developed by separate teams. In other cases, DevOps and application development teams work together on the same cluster. This makes the division of responsibility unclear. If there is an issue with the pod, is it a DevOps issue or an issue for the relevant application team?
Without best practices, clear troubleshooting processes, and the right tools, Kubernetes troubleshooting can quickly become confusing, time consuming, and frustrating, and can impact the reliability of workloads running in a Kubernetes cluster.
Learn more in our detailed guides to Kubernetes Troubleshooting
Or read our guides to the most common Kubernetes errors and how to solve them:
Kubernetes Troubleshooting with Komodor
The troubleshooting process in Kubernetes is complex and, without the right tools, can be stressful, ineffective and time-consuming. Some best practices can help minimize the chances of things breaking down, but eventually something will go wrong – simply because it can.
This is the reason why we created Komodor, a tool that helps dev and ops teams stop wasting their precious time looking for needles in (hay)stacks every time things go wrong.
Acting as a single source of truth (SSOT) for all of your k8s troubleshooting needs, Komodor offers:
- Change intelligence: Every issue is a result of a change. Within seconds we can help you understand exactly who did what and when.
- In-depth visibility: A complete activity timeline, showing all code and config changes, deployments, alerts, code diffs, pod logs and etc. All within one pane of glass with easy drill-down options.
- Insights into service dependencies: An easy way to understand cross-service changes and visualize their ripple effects across your entire system.
- Seamless notifications: Direct integration with your existing communication channels (e.g., Slack) so you’ll have all the information you need, when you need it.
If you are interested in checking out Komodor, use this link to sign up for a Free Trial.
See Additional Guides on Key Kubernetes Topics
Kubernetes ArchitectureAuthored by Komodor |
Kubernetes TroubleshootingAuthored by Komodor |
Kubernetes StorageAuthored by Cloudian |
Argo CDAuthored by Codefresh |
Argo EventsAuthored by Codefresh |
Argo RolloutsAuthored by Codefresh |
Argo WorkflowsAuthored by Codefresh |
Kubernetes DeploymentAuthored by Codefresh |
Kubernetes in AzureAuthored by NetApp |
Kubernetes on AWSAuthored by NetApp |
Kubernetes StatefulsetAuthored by NetApp |
Kubernetes AutoscalingAuthored by Spot.io |
Container SecurityAuthored by Tigera |
Kubernetes SecurityAuthored by Tigera |
Kubernetes NetworkingAuthored by Tigera |
GitOpsAuthored by Mend |
Hybrid ITAuthored by Cloudian |
Kubernetes HelmAuthored by Komodor |
Kubernetes LensAuthored by Komodor |
CI/CDAuthored by Spot |
Additional Kubernetes Resources
Below are additional articles that can help you learn about Kubernetes topics:
- Understanding Kubernetes Logs and Using Them to Improve Cluster Resilience
- How Does CPU Throttling Impact Kubernetes Performance?
- Kubernetes Networking Best Practices
- Understanding Kubernetes Logs and Using Them to Improve Cluster Resilience
- Hybrid Cloud Architecture in 2023: How Does Kubernetes Fit In?
- How Does CPU Throttling Impact Kubernetes Performance?
- What is the Kubernetes Ingress Controller
- 8 Tips for Successful Container Vulnerability Scanning
- Kubernetes Geek Talk: Understanding Pod Status
- K8s Readiness Probe Failed Error
- Kubernetes Resource Requests
- kubectl deploy: Practical Guide to Kubernetes Deployments
- kubectl apply: Syntax, Use Cases, and Best Practices


