What Is Kubernetes Architecture?
Kubernetes is an open source platform for managing Linux containers in private, public, and hybrid cloud environments. Businesses can also use Kubernetes to manage microservices applications.
Kubernetes is an architecture that provides a loosely coupled mechanism for discovering services across a cluster. A Kubernetes cluster has one or more control planes and one or more compute nodes:
- The control plane is responsible for managing the entire cluster, exposing application programming interfaces (APIs), and scheduling the startup and shutdown of compute nodes according to the desired configuration.
- Each compute node runs a Docker-like container runtime with a kubelet, a proxy that communicates with the control plane.
- Each node can be a bare metal server, an on-premises or cloud-based virtual machine (VM).
Understanding the Kubernetes Architecture
Let’s review some of the fundamental concepts of a Kubernetes environment.
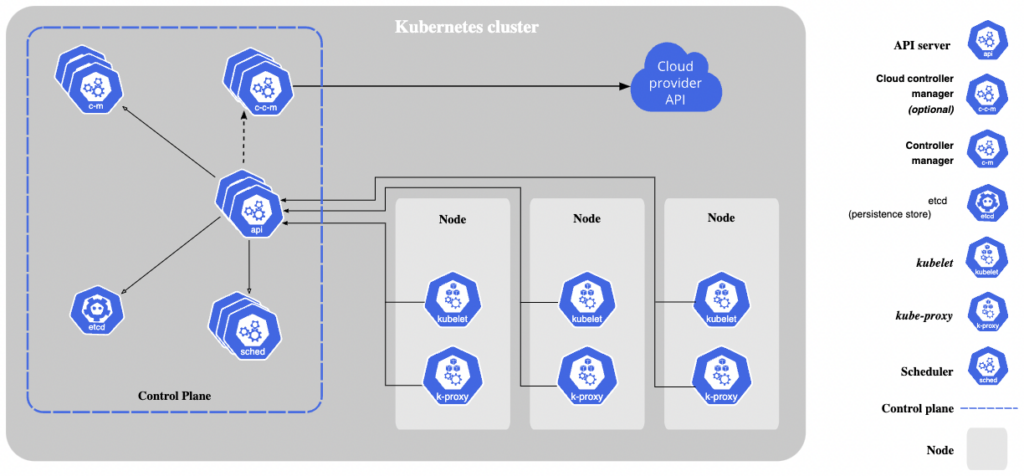
Image Source: Kubernetes
Pod
A pod is a set of containers, the smallest architectural unit managed by Kubernetes. Each pod has an IP address shared by all containers. Resources such as storage and RAM are shared by all containers in the same pod, so they can run as one application.
In some cases, a pod can contain a single container. Multi-container pods, on the other hand, make deployment configuration easier, because they can automatically share resources between containers. This is useful for more complex workload configurations. Many processes work together, sharing the same amount of computing resources.
By default, pods work with temporary storage. This means that if you replace or destroy a pod, its data is lost. However, Kubernetes also supports a persistent storage mechanism called PersistentVolumes.
Deployment
A Deployment allows users to specify the scale at which applications should run. Users need to define replication settings, specifying how the pod should be replicated on Kubernetes nodes.
A Deployment object specifies the default number of clones Kubernetes should create of the same pod. It also specifies a policy for distributing updates. The Deployment adds or removes pods to maintain the desired application state, and tracks pod state to ensure optimal deployment.
Service
In Kubernetes, a Service is an entity that represents a set of pods that run an application or functional component. The service is responsible for maintaining access policies and enforcing these policies for incoming requests.
The need for a Service stems from the fact that pods in Kubernetes are temporary and can be replaced at any time. Kubernetes guarantees the availability of specific pods and replicas, but does not guarantee the uptime of individual pods. This means that Pods that need to communicate with other Pods cannot rely on the IP address of a single primary Pod. Instead, it connects to the service and relays it to the currently running, connected Pod.
The service is assigned a virtual IP address called clusterIP and holds it until it is explicitly destroyed. A service acts as a trusted endpoint for communication between components or applications.
Node
A Kubernetes node is a logical collection of IT resources that supports one or more containers. Nodes contain the services required to run pods, communicate with master components, configure networking, and run assigned workloads. A node can host one or more Pods. Each Kubernetes node has services to create runtime environments and support pods. These components include a container runtime, kube-proxy, and kubelet.
Control Plane
Administrators and users can access Kubernetes through the control plane to manage nodes and workloads. This component controls the interaction between Kubernetes and your applications. You can perform operations via command-line scripts or HTTP-based API calls.
Cluster
A cluster is a collection of all the above components. A cluster contains a Kubernetes control plane and nodes that provide memory and compute resources.
When you add nodes to this “node pool” to scale out the cluster, workloads are rebalanced across the new nodes. Cloud infrastructure such as Google Cloud and AWS help automate cluster management. Users only need to provide their physical specifications and number of nodes, and the cluster can be scaled up and down automatically.
Kubernetes Components
A Kubernetes deployment includes a cluster consisting of one or several worker nodes that run containerized applications. Nodes host pods that include an application workload, and the control plane manages the cluster’s nodes and pods.
In a production environment, the control plane runs across several computers, and the cluster runs multiple nodes to provide high availability and fault tolerance. Here are key components working within the Kubernetes architecture:
Kubernetes Control Plane
Within the Kubernetes architecture, the control plane manages the cluster’s processes, including kube-apiserver, Kubernetes Scheduler, etcd, kube-controller-manager, and cloud-controller-manager. The control plane can also employ third-party solutions, such as cluster-level logging, resource monitoring, and cluster DNS.
kube-apiserver
The Kubernetes API is the core component in every Kubernetes cluster. It manages external and internal traffic, handling API calls related to admission controls, authentication, and authorization. This master component is the front end of every Kubernetes cluster’s shared state. It is the only component that can connect with the etcd database.
etcd
etcd is a database system Kubernetes uses to store networking information, cluster state, and other persistent data. This database stores information as key-value pairs and does not overwrite pairs when an update is required. Instead, it creates a new database entry and appends the end, marking the previous entry for future removal. Each update to the database travels through the kube-api server. The database can work with most HTTP libraries and curl.
kube-scheduler
This component uses various scheduling algorithms to determine which node should host a certain pod. It starts by checking the availability of resources within nodes and then assigns an available node that meets the requirement specified in the request. A node that can satisfy the scheduling requirements is called a feasible node. If a node is not suitable for the pod, it remains unscheduled until a suitable node becomes available.
kube-controller-manager
This control plane component is responsible for running controller processes. Each controller is a different logical process. However, all controllers are compiled into one binary and run in one process to reduce complexity.
Here are commonly-used controllers:
- Node controller—monitors and responds when nodes go down.
- Job controller—looks for job objects representing one-time tasks and creates pods to run these tasks to completion.
- Endpoints controller—populates an endpoints object by joining services and pods.
- Service account & token controllers—create API access tokens and default accounts for new namespaces.
cloud-controller-manager
This controller works similarly to the kube-controller-manager but interacts with cloud-specific APIs. It distinguishes between the components interfacing with a cloud platform and those interacting solely with the cluster.
Node Components
These components run on each node, working to maintain running pods and provide a Kubernetes runtime environment.
kubelet
A kubelet is an agent responsible for communicating with the control plane to ensure the pod’s containers are running. Each node includes a kubelet. It receives pod specifications via the Kubernetes API whenever the control plane requires a specific action to happen in a node and executes this action. It also ensures the relevant containers remain healthy and running.
kube-proxy
A kube-proxy is a network proxy included within each node to facilitate Kubernetes networking services. It can forward traffic or use the operating system’s packet filtering layer to handle network communications inside and outside the cluster.
The kube-proxy ensures services are available to external parties and handles individual host subnetting. It works as a service load balancer and network proxy on each node, managing network routing for TCP and UDP packets and routing traffic for all service endpoints.
Add-Ons
Add-ons utilize Kubernetes resources, such as Deployments and DaemonSets, to implement various cluster-level features that extend the functionality of Kubernetes. All namespaced resources for Kubernetes add-ons work within the kube-system namespace.
Cluster DNS
This DNS server serves DNS records to Kubernetes. Every cluster should include this add-on as it provides a lightweight mechanism in service discovery. Containers started by Kubernetes come with a DNS server in their DNS lookups.
Web UI (Dashboard)
The Kubernetes dashboard provides a web-based, general-purpose user interface (UI) for Kubernetes clusters. It enables troubleshooting and managing a cluster and the applications it runs.
Cluster-Level Logging
Application logs provide visibility into what occurs inside an application. This information helps debug issues and monitor cluster activity. Cluster-level logging involves setting separate storage for cluster logs and ensuring these logs follow a lifecycle that is independent of containers, pods, or nodes.
A cluster-level logging architecture requires a separate backend for storing, analyzing, and querying logs. However, Kubernetes does not come with native storage for logs. Instead, it allows integration with third-party logging solutions.
Kubernetes Operator
A Kubernetes Operator is a way to package, deploy, and manage a Kubernetes application. An Operator is a method of implementing human operational knowledge as code, which can then be used to automate the management of applications on Kubernetes.
Operators follow the principles of the Operator pattern, which is a way to extend the Kubernetes API to create custom resources that represent the desired state of a complex application. The Operator is responsible for reconciling the current state of the application with the desired state, by using the Kubernetes API to make the necessary changes.
Operators can be used to automate tasks such as rolling updates, backups, and disaster recovery for complex applications. They can also make it easier to deploy and manage applications on Kubernetes by encapsulating the complex logic required to run the application in a simple, declarative configuration.
Securing Your Kubernetes Architecture
Designing a secure Kubernetes architecture involves implementing a set of best practices and technologies to ensure the confidentiality, integrity, and availability of your containerized applications. Here are some key considerations for designing a secure Kubernetes architecture.
Managed vs. Self-Managed Kubernetes Services
Managed Kubernetes services are provided by cloud providers and other third-party vendors, and they handle the maintenance and operation of the Kubernetes cluster for you. Self-managed Kubernetes services, on the other hand, require you to set up and manage the Kubernetes cluster yourself.
Managed Kubernetes services can be more convenient and require less expertise to set up and maintain, but they may also be more expensive than self-managed services. Managed Kubernetes architectures often come with a range of security features and tools, such as network security, identity and access management, and container security, which can help improve the overall security posture of your cluster.
They also typically include ongoing maintenance and updates to ensure that the cluster is secure and compliant. This can help reduce the burden of security maintenance on your team and allow you to focus on developing and deploying your applications.
However, while managed Kubernetes architectures can provide enhanced security features and maintenance, they may also introduce additional security risks. For example, you may need to trust the third-party vendor to properly secure and manage the cluster, and you may not have as much control over the security configuration of the cluster as you would with a self-managed architecture.
Learn more in our detailed guides to:
- Kubernetes service
- Kubernetes cluster (coming soon)
Single-Cluster vs. Multi-Cluster Architecture
A single-cluster architecture involves running all of your workloads in a single Kubernetes cluster. A multi-cluster architecture involves running multiple Kubernetes clusters, potentially in different regions or cloud providers. Single-cluster architectures can be simpler to set up and manage, but they may not be as scalable or resilient as multi-cluster architectures.
Single vs. Multiple Namespaces
A namespace in Kubernetes is a logical boundary for resources within a cluster. Using multiple namespaces can help you organize your resources and provide isolation between different teams or environments. However, managing multiple namespaces can also be more complex than using a single namespace.
Service Meshes
A service mesh is a network of microservices that provides a secure communication layer between your services. By using a service mesh, you can enforce security policies, control access to your services, and monitor traffic between your services.
A service mesh can help you control access to your services, allowing you to specify which services are allowed to communicate with each other and which are not. This can help prevent unauthorized access to your services and protect against attacks such as injection attacks and man-in-the-middle attacks. It can also help you monitor traffic between your services.
However, one potential downside is that implementing a service mesh can be complex and may require significant resources and expertise.
External Monitoring and Security Software
Implementing external monitoring tools and services can help you detect and respond to security threats and vulnerabilities in your Kubernetes environment. These tools can monitor your cluster for suspicious activity, alert you to potential security issues, and provide insights into the overall security posture of your cluster.
There are various security software tools and services that you can use to secure your Kubernetes environment. These include tools for network security, container security, and identity and access management.


