Kubernetes is a quintessential operating system for the cloud, providing a platform for the deployment, scaling, and management of containerized microservice applications. At the heart of Kubernetes is the Kubernetes API, which serves as the primary entry point for interacting with the system. The official client for the Kubernetes API is kubectl, a Kubernetes CLI tool that allows users to manage a Kubernetes cluster and perform a wide range of tasks.
Kubernetes, also known as K8s, is a complex system. Managing a cluster through kubectl can be challenging, especially for users who are not experienced with the tool or have yet to develop a deep understanding of Kubernetes. When kubectl users lack experience or knowledge, they may encounter difficulties while using the tool, causing frustration and possibly even the failure of deployments.
This article explores common mistakes and misunderstandings that can lead to problems leveraging kubectl—and strategies for avoiding or resolving them. Both seasoned Kubernetes users and newcomers to the platform will find valuable insights and tips for using kubectl effectively.
The first step is understanding how Kubernetes manages resources and enables users to interact with them.
Kubernetes Object Management
Several management techniques can be used when working with Kubernetes and kubectl. These techniques involve different approaches to defining and modifying a Kubernetes cluster and its objects:
- Imperative commands: Use kubectl to directly execute actions on the cluster, such as creating or deleting objects or modifying their attributes. This technique is useful for performing a specific task or making a quick change to the cluster.
- Imperative object configuration: Use kubectl to create or modify object configurations in real time with a configuration file.
- Declarative object configuration: Define the desired state of the resources in a configuration file and then use kubectl to apply the configuration to the cluster. This process follows the GitOps principles and is repeatable and therefore appropriate to use in configuration management systems or continuous delivery pipelines.
Imperative commands and imperative object configuration are helpful for quick and direct actions, such as troubleshooting or creating temporary deployments. On the other hand, declarative object configuration is a more structured and repeatable approach and more appropriate for production; however, it requires more significant work in defining the desired state of the cluster.
Five Big Gotchas in kubectl
With nearly 50 commands and 40 flags, kubectl is a powerful command-line tool for managing Kubernetes resources and clusters. Although it is robust and comprehensive, it can be complex and challenging. While using kubectl, there are multiple ways to execute the same tasks and, unfortunately, some wrong ways to do them too. To use kubectl effectively, it is important to have a solid understanding of Kubernetes concepts and architecture. This includes knowing how to deploy and manage applications on a Kubernetes cluster, as well as how to troubleshoot issues that may arise.
Here are the five main issues that novice Kubernetes users can encounter while using kubectl:
1. Using kubectl requires knowledge and expertise
One challenge that many users of kubectl face is the complex querying, messages and outputs that the Kubernetes API returns. Many of the status messages that kubectl displays require a high level of Kubernetes knowledge and experience to understand and can be difficult for those new to Kubernetes to interpret. For example, messages like ImagePullBackOff, ErrImagePull, or CrashLoopBackOff can be confusing for those unfamiliar with these concepts and may require further research to understand comprehensively. Even experienced developers often need to Google search various outputs from kubectl to fully understand what they mean.
To get you started here’s the Ultimate kubectl Cheat Sheet.
2. Finding Root Causes in a Cluster
With kubectl, users can check the status of various resources, such as pods, deployments, and services, to understand what might be causing problems in a cluster. Yet finding the root cause of issues in a cluster is not always straightforward.
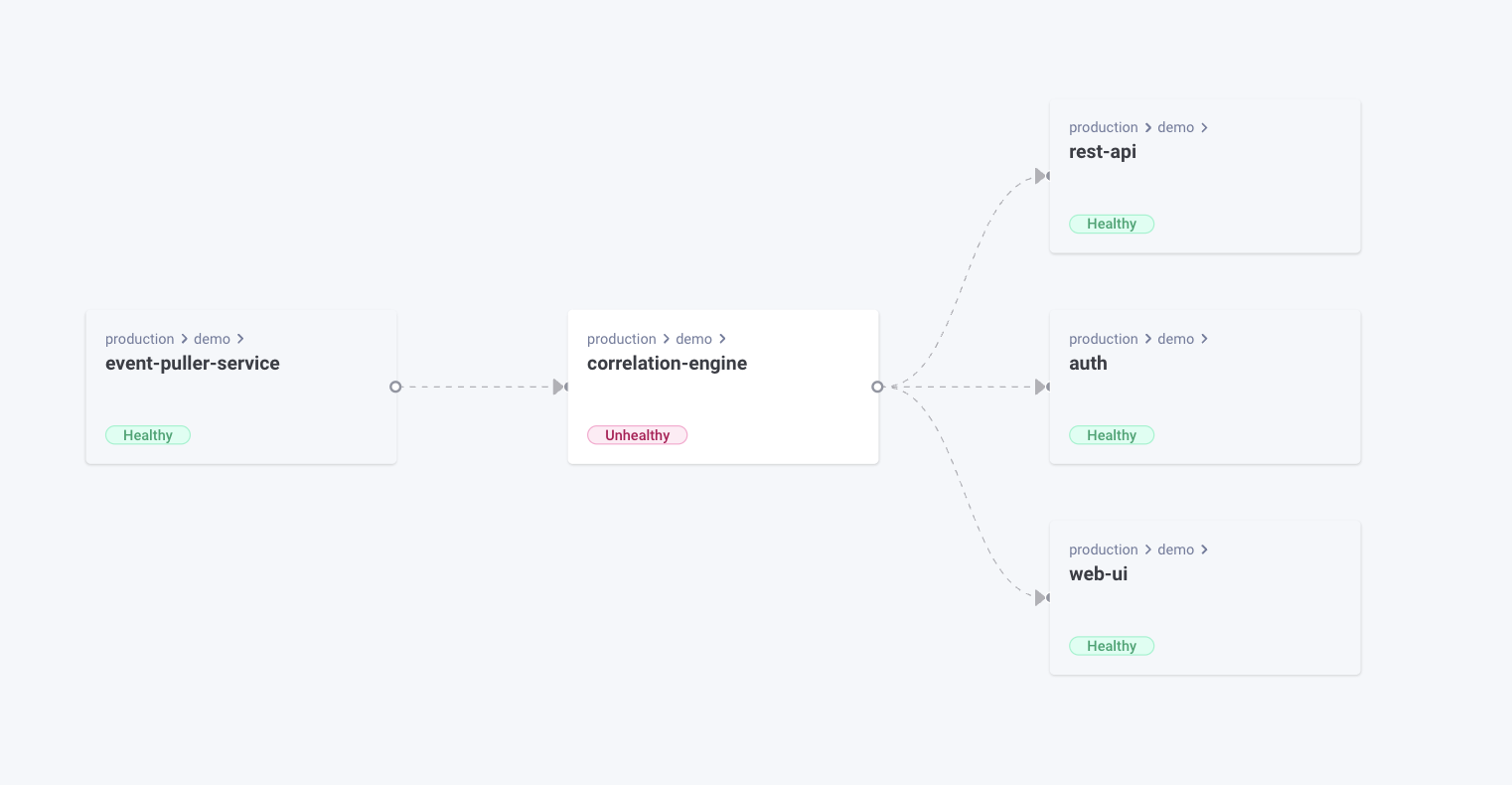
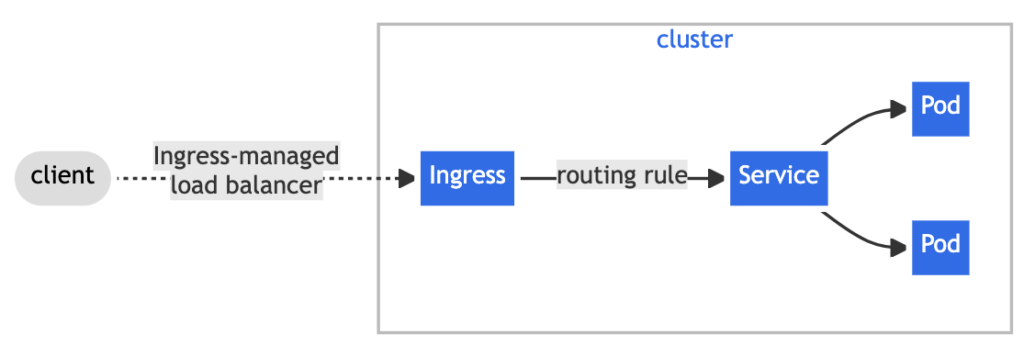
To use kubectl effectively for root cause analysis, a user must know what they are looking for in the cluster and how to describe resources and find the divergences between them. They may also need to dig deeper into the cluster to understand the connections between different resources. Let’s assume an ingress is not reachable from its external URL. Troubleshooting requires the knowledge that the ingress is managed by an ingress controller, backed up by a service, and that the service connects to a port in one of the selected pods:
3. Lack of Debugging Commands
While kubectl does have a kubectl exec command that allows users to dive into a container and run commands within it, this command can be limited in its usefulness for debugging. In many cases, there may not be any debugging tools installed within the container—such as distroless images—making it difficult to troubleshoot issues that arise.
One workaround for this issue is running sidecar containers with installed debugging tools. This workaround can be a helpful way to gain visibility into the inner workings of an application, but it requires a thorough understanding of the application architecture, ports, and configuration. Users will need to know which containers are running, how they are connected, and the configuration of the debugging tools in use.
4. Configuration Drift
Configuration drift occurs when the configuration of a resource in the cluster no longer matches the configuration specified in the source code, an issue which can happen when the configuration is changed directly in the cluster with imperative commands, rather than being updated through the source code. Although changing the configuration in the cluster in this manner sounds like a reasonable solution for troubleshooting, quick fixes, or security patches, it makes it extremely difficult to manage clusters in the long run. Therefore, to prevent configuration drift and management issues, it is best practice to update the configuration in the source code and only then use kubectl.
5. Context and Namespace Management
A kubeconfig file with multiple contexts can be dangerous, as it can lead to accidentally deploying new versions of applications to the wrong clusters. To avoid this issue, it is essential to carefully manage kubeconfig files and pay attention to the context currently in use.
There are tools and plugins available, such as kubens and kubectx, to easily switch between contexts and namespaces, making it easier to manage applications on a Kubernetes cluster. Staying cautious is important, even when using tools and plugins. Deployment to the wrong cluster or namespace can result in data leaks, data loss, and downtime.
Wrapping it up
Kubernetes is a popular and reliable platform in cloud computing, and its command-line tool, kubectl, is one means of troubleshooting issues on a Kubernetes cluster. However, using kubectl effectively requires a good understanding of Kubernetes concepts and architecture and familiarity with the command-line interface. It can be challenging for those new to Kubernetes or those unfamiliar with command-line tools to use kubectl effectively.
For long-term success, a Kubernetes-native troubleshooting tool must be used to quickly find and fix issues in clusters. With the right tools and knowledge, users can effectively manage and troubleshoot applications on a Kubernetes cluster.
Komodor is a Kubernetes operations platform for developers. Complete with automated playbooks for every Kubernetes resource, and static-prevention monitors that enrich live and historical data with contextual insights.
By baking Kubernetes expertise directly into the product, Komodor is accelerating development cycles, reducing MTTR, and empowering dev teams to manage their Kubernetes apps efficiently and independently.
Simplify your Kubernetes operations now! Sign up for your free trial of Komodor.